CAREER: Integrated Load and Resource Management for High-Utilization Datacenters
PI: Ahmed Saeed - Georgia Tech
PI: Ahmed Saeed - Georgia Tech
Modern cloud services rely on expensive and power-hungry hardware, making efficient use of computing resources essential for controlling cost and energy consumption. This project focuses on maximizing how much useful work each server can perform without becoming overloaded or unresponsive. The central idea is to make cloud systems decide how much work a server can handle before accepting new requests, assign resources to individual tasks accordingly, and then distribute incoming work across servers based on these decisions. Today, resource allocation and load distribution are handled separately. This project brings them together and makes these capabilities easier for users to adopt. The overall goal is to improve cloud services without constantly adding more hardware.
The intellectual merit of the project lies in a coordinated redesign of load and resource management across software and hardware layers. This problem is fundamentally challenging because resource demands vary widely across requests, bottlenecks shift over time, and independent control mechanisms often operate at similar timescales and interfere with each other. Addressing these challenges requires fine grained visibility into application behavior and new control abstractions that can coordinate decisions across layers without introducing excessive overhead. The work is organized around three technical thrusts. The first thrust develops unified and transparent mechanisms that track resource usage for each application request and enforce admission decisions across multiple shared bottlenecks. The second thrust integrates these decisions with operating system scheduling, jointly managing application load and the resources allocated to handle it. The third thrust extends these ideas to clusters of servers, redesigning load balancing, backpressure, and scaling mechanisms for applications built as chains of microservices.
The broader impacts of this project include improved performance, lower cost, and reduced energy use for cloud services that support the modern economy. By reducing the need for over provisioned computing resources, the project contributes to more sustainable and environmentally responsible infrastructure. The resulting tools will help application developers build faster and more predictable systems without deep expertise in low level resource management. Educational activities will integrate the research into courses, seminars, and online programs, preparing students for careers in computing systems while encouraging innovation through hands on projects and research experiences.
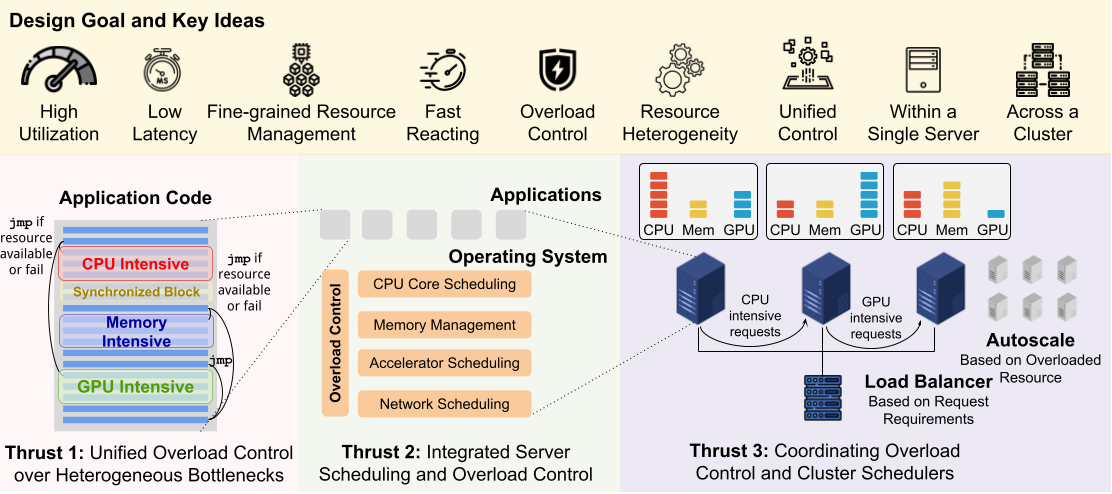
The figure summarizes the three thrusts of the proposed research, each characterized by a different scale of investigation. Starting from the scale of a single application, we will develop a holistic overload controller that can track all resources and react to per-request behavior, depending on the execution path taken by the specific request. At the server level, we will integrate overload control and resource scheduling decisions for all applications running on the server, focusing on CPU and GPU use cases. At the cluster level, we will explore mechanisms that can leverage fine-grained control at the server level to improve decision making when scheduling multiple servers (e.g., load balancing). In particular, we will pursue the following thrusts:
TBD
TBD
TBD